Step & Pipeline
A pipeline is a machine learning workflow, consisting of one or more steps, to deploy containerised code. Like a regular function, a step is defined by the input it ingests, the code it runs, and the output it returns. You can then create a full pipeline formed with a computed acyclic graph (DAG) by specifying the output of one step as the input of another step.
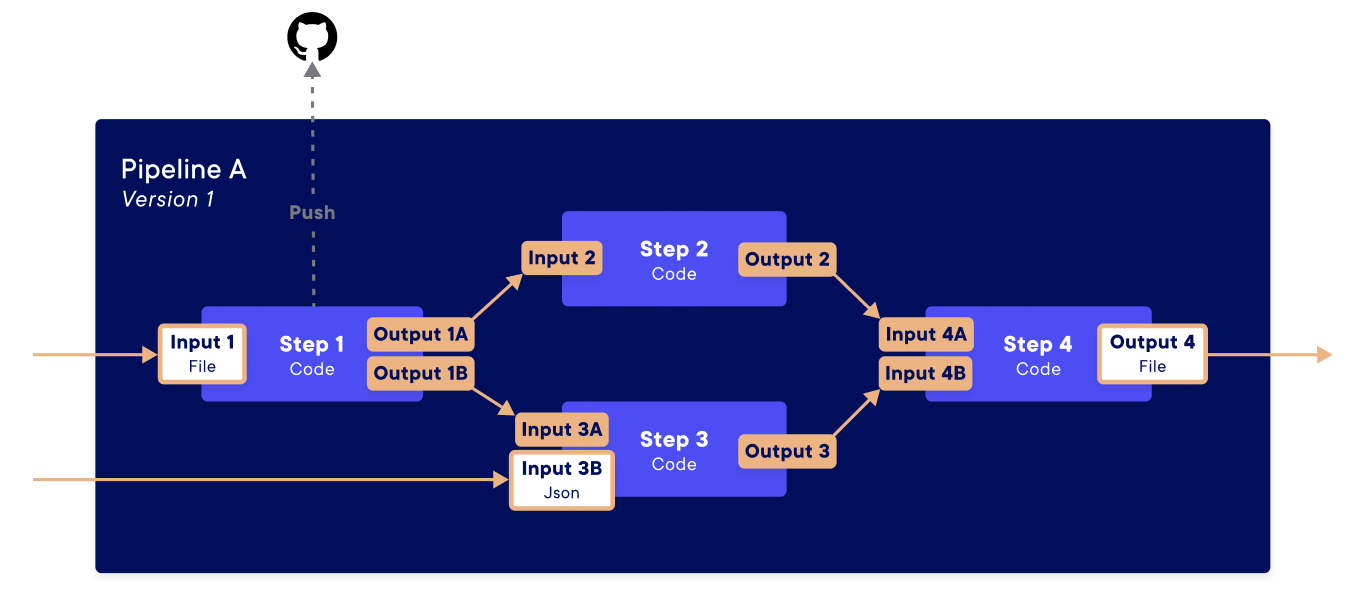
💡 The pipelines are written in Python with SDK calls for an easy authoring experience and executed on Kubernetes for scalability. The pipelines’ functioning are based on the open-source library Argo. Each step deploy is containerised with Docker.
The main objectives of the steps and pipelines are :
- Orchestrating end-to-end ML workflows
- Increasing reusability of Data Science components from a project to another
- Collaboratively managing, tracking and viewing pipeline definitions.
- Deploying in production in few clicks with several methods (endpoint, CRON, manual, …)
- Enabling large scale production of Python code without refactoring to a more production friendly language
- Ensuring an efficient use of compute resources, thanks to Kubernetes
Example :
🖊️ Training pipeline
- Data preparation and preprocessing: In this stage, raw data is collected, cleaned, and transformed into a format that is suitable for training a machine learning model. This may involve tasks such as filtering out missing or invalid data points, normalizing numerical values, and encoding categorical variables.
- Model training: In this stage, a machine learning model is trained on a prepared dataset. This may involve selecting a model type, tuning hyperparameters, and training the model using an optimization algorithm.
- Model evaluation: Once the model has been trained, it is important to evaluate its performance to determine how well it generalizes to new data. This may involve tasks such as splitting the dataset into a training set and a test set, evaluating the model’s performance on the test set, and comparing the results to a baseline model.
🖊️ Inference pipeline
- Model loading: In this stage, a trained machine learning model is loaded from storage and prepared for use. This may involve tasks such as loading the model’s weights and any associated dependencies.
- Data preparation: In this stage, incoming data is cleaned and transformed into a format that is suitable for the model. This may involve tasks such as normalizing numerical values and encoding categorical variables.
- Inference: In this final stage, the model is used to make predictions on the prepared data. This may involve tasks such as passing the data through the model and processing the output to generate a final prediction.