Deployment
A deployment is a way to trigger an execution of a Machine Learning pipeline in a repeatable and automated way. Each pipeline can be associated with multiple deployments.
For each deployment, you can use 2 distinct execution rules :
- by endpoint (web API)
- by periodic trigger (CRON)
In addition, for each deployment, you will need to connect the pipeline inputs and outputs with the desired sources and destinations. When one of the deployment conditions is met, the pipeline is executed by using the computing resources available in its environment.
The results of the execution (predictions, metrics, data, ...) can be stored in the data store of the environment and can be easily retrieved by the users. You can find all the information about the executions in the execution tracking section.
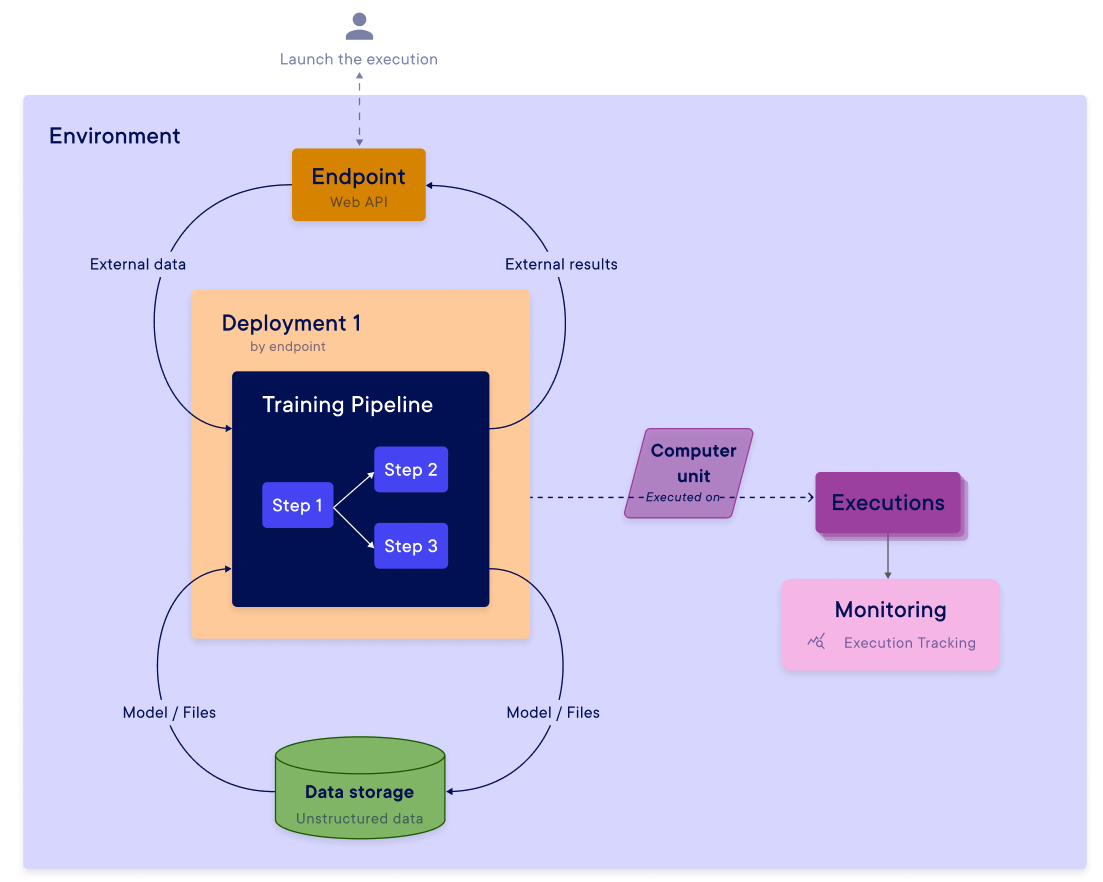
In addition to the deployment functionality, it is possible to run a pipeline directly without deploying it. This allows you to run your pipeline on the fly without having to create a specific deployment, which is very useful during the experimentation phase.
The main objectives of the deployments are :
- No longer take 6 months to deploy ML models in production but a few clicks!
- Automating the execution of the pipelines to save time for Data Science teams
- Creating secured web API to deliver pipeline results to external users without any DevOps skills
- Automatically triggering re-training pipelines when model performance drops
- Visualizing pipeline executions, experiment tracking, and ML artifacts