Create a pipeline
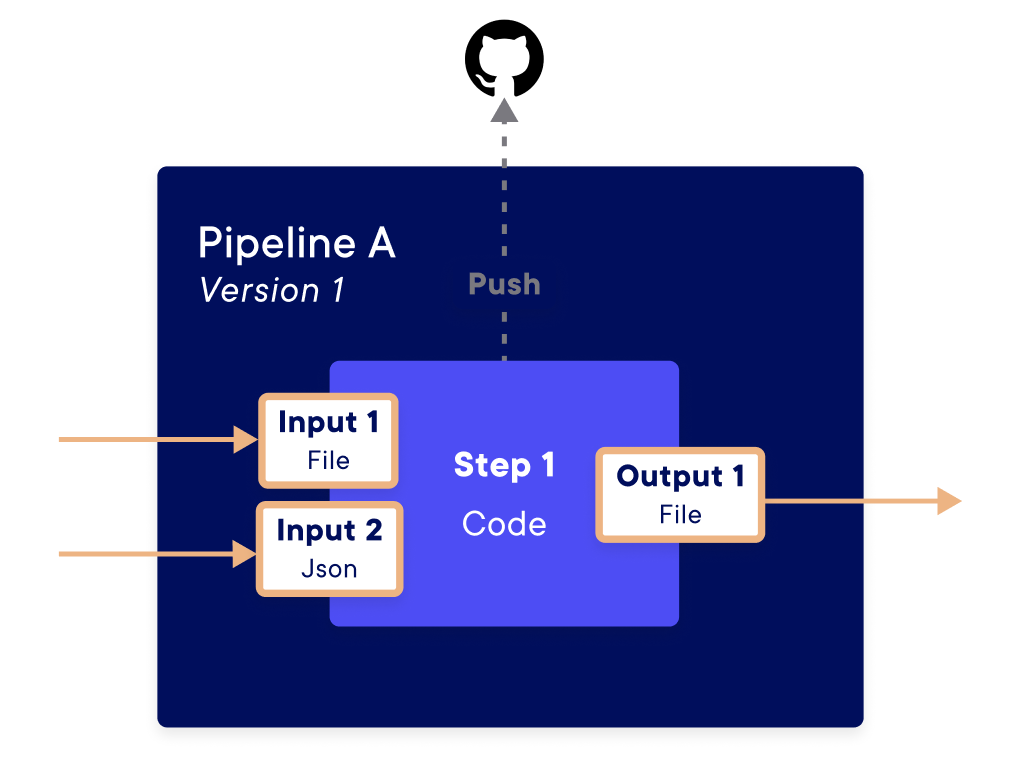
A pipeline is an atomic component defined by its input and output parameters and by the processing it applies. In practice, a pipeline is a function with inputs and outputs coded in Python. The Python code (currently the only available language) used by the pipeline is stored in a folder on your local machine or in a Git repository.
An input of a pipeline is an object you can use inside the code. An output of a pipeline is defined from the results of the pipeline function.
Each pipeline is considered as a specific container that is executed on Kubernetes.
The pipelines are stored in a specific environment, and only people with access to this environment can read and write the pipelines. By default, each pipeline uses the values defined in the project settings. However, these values can be overridden in the pipeline creation parameters, as detailed below.
Summary
| Function name | Method | Return type | Description |
|---|---|---|---|
| Input | Input(name, data_type="string", description="", is_required=False, default_value=None) | Input SDK Object | Create an Input object to give at create_pipeline() function for pipeline a pipeline input. |
| Output | Output(name, data_type="string", description="") | Output SDK Object | Create an Output object to give at create_pipeline() function for pipeline a pipeline output. |
Prepare your code
[Optionnal] Use a Git repository
In case you want to retrieve your source code from a GitHub repository instead of a local folder, some additional steps are necessary. More details can be found here.
Currently you can create a pipeline using the Python SDK, but not using the GUI. However, once you have created the pipeline, you will be able to see it on the UI platform.
If it’s not already done, put the code of the pipeline into a single folder, which will be sent to the platform. The file with the entry function of your pipeline can be anywhere in your folder.
Example file tree:
Example my_entry_function_pipeline.py:
import numpy as np
# and other import
def entryPipeline(dataX_input, dataY_input) :
# Some machine learning code
return result_output
If you prefer, you can also use a GitHub repository instead of a local folder. More information can be found here.
Define pipeline inputs and outputs
A pipeline may need to receive some information or give some result (just
like a function). To do that, we use Input and Output object. These
objects allow defining the properties of the input or output that will
be expected in the pipeline. The input and output objects thus created must
be given as a parameter of the pipeline creation. Each input is defined as
an Input object and, each Output is defined as an Output object,
through a class available in the SDK.
Input object definition
from craft_ai_sdk.io import Input
Input(
name="*your_input_name*",
data_type="*your_io_data_type*",
description="",
is_required=True
default_value="*default_value*"
)
Parameters
-
namejust a name for identifying the input later. -
data_type, one of the following possible types: -
file: reference to binary data, equivalent to a file’s content. If the input/output is not available, an empty stream. -
json: JSON-serializable Python object. The following sub-types are provided for more precise type checking, but they are all JSON -
string -
number -
arrayofJSON -
booleanIf the input/output is not available, None in Python
-
default_value(optional) - If the parameter is empty, this value will be set by default. If a deployment receives an empty parameter and already put a default value in the input, the default value of deployment will be keep. -
is_required(optional,Trueby default) - Push an error is the input is empty. -
description(optional) - This parameter precise what it’s expected in this input. It’s not read by the machine, it’s like a comment.
Return
No return
Output object definition
from craft_ai_sdk.io import Output
Output(
name="*your_input_name*",
data_type="*your_io_data_type*",
description="",
)
Parameters
-
namejust a name for identifying the input later. -
data_type, one of the following possible types: -
file: reference to binary data, equivalent to a file’s content. If the input/output is not available, an empty stream. json: JSON-serializable Python object. The following sub-types are provided for more precise type checking, but they are all JSONstringnumberarrayofJSONboolean
If the input/output is not available, None in Python
description(optional) - This parameter precise what it’s expected in this input. It’s not read by the machine, it’s like a comment.
Return
No return
Note
You can use craft_ai_sdk.INPUT_OUTPUT_TYPES to get all possible types in Input and Output objects.
List of all possible types :
ARRAY= "array"BOOLEAN= "boolean"FILE= "file"JSON= "json"NUMBER= "number"STRING= "string"
Example :
from craft_ai_sdk.io import Input, INPUT_OUTPUT_TYPES
Input(
name="inputName",
data_type=INPUT_OUTPUT_TYPES.JSON,
)
Example for input and output
Input(
name="inputName",
data_type="string",
description="A parameter for pipeline input",
is_required=True,
default_value="default_content_here"
)
Output(
name="inputName",
data_type="string",
description="A parameter for pipeline input",
)
Warning
The size of the I/O must not exceed 0.06MB (except for file type).
Create your pipeline
Function definition
Create pipelines from a source code located on a local folder or a Git repository.
sdk.create_pipeline(
function_path="src/my_reusable_funtion.py",
function_name="my_function",
inputs=[Input(...)],
outputs=[Output(...)],
pipeline_name="pipeline-name", # by default its the function name
description="text desciption",
timeout_s=180,
container_config = {
language="python:3.8-slim",
repository_url="your-git-url",
repository_branch="*your-git-branch* or *your-git-tag*",
repository_deploy_key="your-private_key",
requirements_path="your-path-to-requirements.txt",
included_folders=["your-list-of-path-to-sources"],
system_dependencies=["package_1", "package_2"],
dockerfile_path="dockerfile",
local_folder="*my-local-folder-path*"
},
)
Parameters
-
function_path(str) – Path to access to the file who had the entry function of the pipeline. -
function_name(str) – Function name of entry function pipeline. -
inputs(list<Input>) – List of pipeline inputs. -
outputs(list<Output>) – List of pipeline outputs. -
pipeline_name(str) – pipeline name. By default, it’s the function name. The name must be unique inside an environment and without special character ( - _ & / ? …) -
description(str, optional) – Description of the pipeline, it’s no use by the code, it’s only for user. -
timeout_s(int, optional) – Maximum time to wait for the pipeline to be created. 3min by default, and must be at least 2min. -
container_config(dict, optional) – Dict Python object where each key can override default parameter values for this pipeline defined at project level. -
language(str, optional) – Language and version used for the pipeline. Defaults to falling back on project information. The accepted formats arepython:3.X-slim, where3.Xis a supported version of Python, andpython-cuda:3.X-Y.Zfor GPU environments, whereY.Zis a supported version of CUDA. The list of supported versions is available here. repository_url(str, optional) – Remote repository URL.repository_branch(str, optional) – Branch name for Git repository. Defaults to None.repository_deploy_key(str, optional) – Private SSH key related to the repository.requirements_path(str, optional) – Path to the file requirement for Python dependency.included_folders(list, optional) – List of folders that need to be accessible from pipeline code.system_dependencies(list, optional) – List of APT Linux packages to install.dockerfile_path(str, optional) – Path to a docker-file for having a custom config in pipeline. (see the part after for more detail)local_folder(str, optional): Path to local folder where the pipeline files are stored, if not on a Git repository.
Note
The repository_branch parameters as well as the container_config elements (except dockerfile_path) can take one of the STEP_PARAMETER object's values in addition to theirs.
In fact, STEP_PARAMETER allows us to specify at the pipeline level whether we want to take the project's values (default behavior) or define a null value:
STEP_PARAMETER.FALLBACK_PROJECT: Allows to take the value defined in the project parameters (default behavior if the field is not defined).STEP_PARAMETER.NULL: Allows to set the field to null value and not to take the value defined in the project.
Example with a code pipeline that does not need a requirement.txt and does not take the one defined in the project settings:
from craft_ai_sdk import STEP_PARAMETER
# Code for init SDK here ...
sdk.create_pipeline(
function_path="src/helloWorld.py",
function_name="helloWorld",
pipeline_name="my_pipeline_name",
container_config = {
"requirements_path": STEP_PARAMETER.NULL,
}
)
Warning
The size of the embedded code from your folder / Git repository must not exceed 5MB.
You can select the part of your folder / Git repository to import using the included_folders parameter.
If the data you want to import is larger than 5MB, you can use the data store to store it and then import it into your pipeline.
Returns
The return type is a dict with the following keys :
parameters(dict): Information used to create the pipeline with the following keys:pipeline_name(str): Name of the pipeline.function_path(str): Path to the file that contains the function.function_name(str): Name of the function in that file.description(str): Description.inputs(list of dict): List of inputs represented as a dict with the following keys:name(str): Input name.data_type(str): Input data type.is_required(bool): Whether the input is required.default_value(str): Input default value.
outputs(list of dict): List of outputs represented as a dict with the following keys:name(str): Output name.data_type(str): Output data type.description(str): Output description.
container_config(dict[str, str]): Some pipeline configuration, with the following optional keys:language(str): Language and version used for the pipeline. Defaults to falling back on project information. The accepted formats arepython:3.X-slim, where3.Xis a supported version of Python, andpython-cuda:3.X-Y.Zfor GPU environments, whereY.Zis a supported version of CUDA. The list of supported versions is available here.repository_url(str): Remote repository url.repository_branch(str): Branch name.included_folders(list[str]): List of folders and files in the repository required for the pipeline execution.system_dependencies(list[str]): List of system dependencies.dockerfile_path(str): Path to the Dockerfile.requirements_path(str): Path to the requirements.txt file.
creation_info(dict): Information about the pipeline creation:created_at(str): The creation date in ISO format.updated_at(str): The last update date in ISO format.commit_id(str): The commit id on which the pipeline was built.status(str): The pipeline status, if the pipeline creation process is under 2m40s (most of the time it is), is alwaysReadywhen this function returns.origin(str): The origin of the pipeline, can begit_repositoryorlocal.
Liste of language available
When using a CPU environment, the language parameter must be :
python:3.8-slim.python:3.9-slimpython:3.10-slim
When using a GPU environment, the language parameter must be :
- For cuda v11.8
python-cuda:3.8-11.8python-cuda:3.9-11.8-
python-cuda:3.10-11.8 -
For cuda v12.1
python-cuda:3.9-12.1python-cuda:3.10-12.1
You can also use the CPU image in a GPU environment if you don't need access to the GPU.
Example: Create pipeline from scratch
Function usage
from craft_ai_sdk import Input, Output
input1 = Input(
name="input1",
data_type="string",
description="A parameter named input1, its type is a string",
is_required=True,
)
input2 = Input(
name="input2",
data_type="file",
description="A parameter named input2, its type is a file"
)
input3 = Input(
name="input3",
data_type="number",
)
prediction_output = Output(
name="prediction",
data_type="file",
default_value="default,content,here",
)
pipeline = sdk.create_pipeline(
function_path="src/my_reusable_funtion.py",
function_name="my_function",
description="Apply the model to the sea",
container_config = {
"local_folder": "my/path/",
},
inputs_list=[input1, input2, input3],
outputs_list=[prediction_output],
## ...
)
Download pipeline local folder
Function definition
Download a pipeline's local folder as a .tgz archive. Only available if the pipeline's origin is local_folder. This contains the files that were included in the local_folder parameter provided during pipeline creation, and that were filtered based on the container_configuration, which can be defined in project information or in pipeline creation parameters.
Parameters
pipeline_name(str) – Name of the pipeline to be downloaded.folder(str) – Path to the folder where the file will be saved.
Returns
None