Deploy a LM Pipeline
The basic usecase of the Platform is to launch pipelines that are executing ML algorithms. Here is the full step-by-step guide on how to do that. You'll just need to adapt it to your own usecase !
Overview & Setup
Prerequisites
- Python 3.9 or higher is required to be installed on your computer.
- Have followed the Setup from the
Get Started&& therequirements.txtfile presented in the Project - Install the packages craft-ai-sdk numpy python-dotenv pandas scikit-learn pyarrow joblib using the command
- All the code presented in this tutoriel can be found here.
- For all questions you may have on the SDK functions, please refer to the SDK Documentation.
We will build a pipeline to train and store a simple ML model that is interacting with the iris dataset. The iris dataset describes four features (petal length, petal width, sepal length, sepal width) from three different types of irises (Setosa, Veriscolour, Virginica).

The goal of our application is to classify flower type based on the previous four features. We will fetch the dataset from its public library, build a pipeline to train a simple ML model on it and store this model on the Data Store. for more informations on the Datastore itself, please refer to the Datastore documentation.
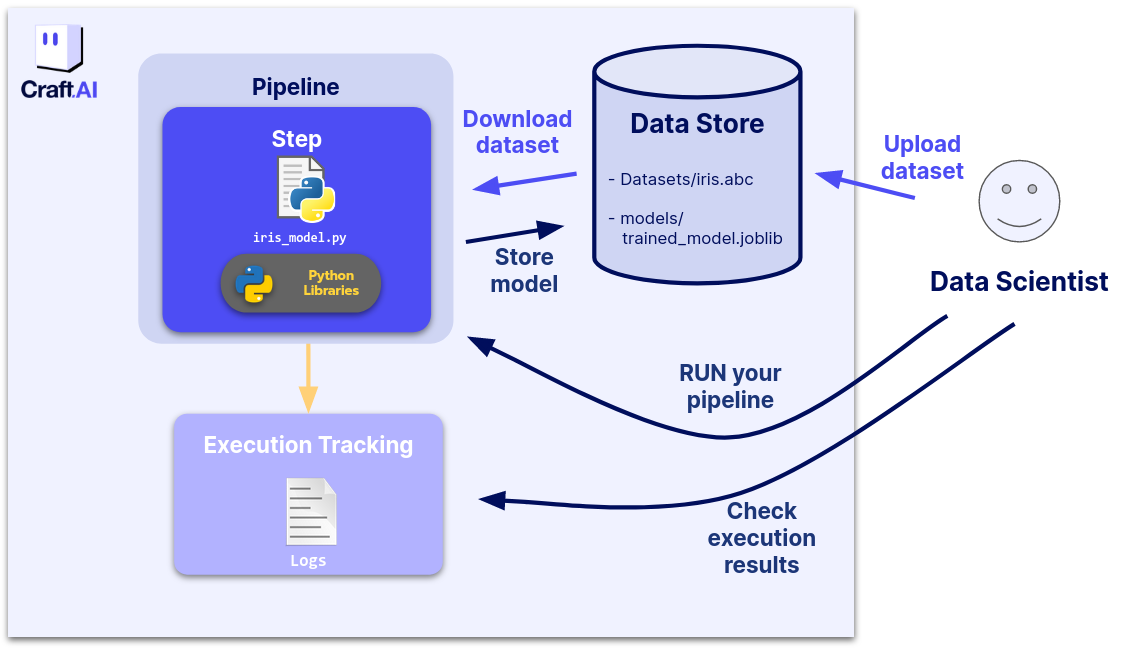
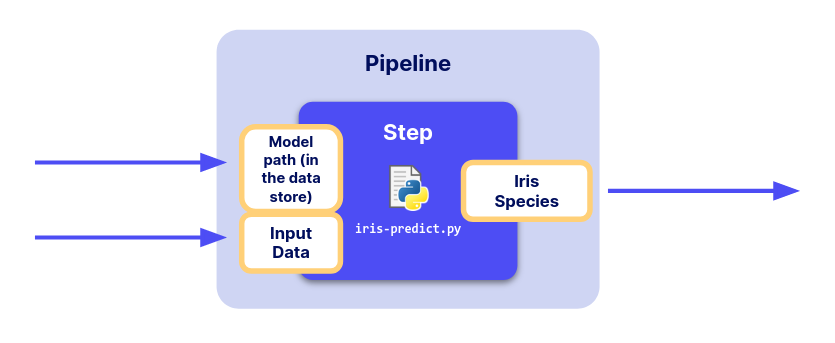
To do this, we will create a pipeline that has Inputs and an Output, thus exploit key fonctionalities of the Platform.
First, we need to store the dataset on the Datastore. Please, run this code in your terminal :
from io import BytesIO
from sklearn import datasets
import pandas as pd
iris = datasets.load_iris(as_frame=True)
iris_df = pd.concat([iris.data, iris.target], axis=1)
file_buffer = BytesIO(iris_df.to_parquet())
sdk.upload_data_store_object(
filepath_or_buffer=file_buffer,
object_path_in_datastore="get_started/dataset/iris.parquet"
)
Create & run the complete ML pipeline
Train the model
To train our model, we need to declare it and store it in a pipeline. To do so, please, create a python file, for the exercice, we named it iris-train.py
import joblib
import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from craft_ai_sdk import CraftAiSdk
def trainIris():
sdk = CraftAiSdk()
sdk.download_data_store_object(
object_path_in_datastore="get_started/dataset/iris.parquet",
filepath_or_buffer="iris.parquet",
)
dataset_df = pd.read_parquet("iris.parquet")
X = dataset_df.loc[:, dataset_df.columns != "target"].values
y = dataset_df.loc[:, "target"].values
np.random.seed(0)
indices = np.random.permutation(len(X))
n_train_samples = int(0.8 * len(X))
train_indices = indices[:n_train_samples]
val_indices = indices[n_train_samples:]
X_train = X[train_indices]
y_train = y[train_indices]
X_val = X[val_indices]
y_val = y[val_indices]
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
mean_accuracy = knn.score(X_val, y_val)
print("Mean accuracy:", mean_accuracy)
joblib.dump(knn, "iris_knn_model.joblib")
sdk.upload_data_store_object(
"iris_knn_model.joblib", "get_started/models/iris_knn_model.joblib"
)
And then, create the pipeline in your terminal, using this command :
sdk.create_pipeline(
pipeline_name="iris-train",
function_path="iris-train.py",
function_name="trainIris",
description="This function creates a classifier model for iris",
container_config = {
"local_folder": "src", # Enter the path to your local folder here
}
)
Once the creation finished, run it.
Now, we do have our dataset and model created and stored on the Datastore.
Create the prediction pipeline
Then, we need to create the prediction pipeline. Please create a file (here, named iris-predict.py) with the following content :
from io import BytesIO
from craft_ai_sdk import CraftAiSdk
import joblib
import pandas as pd
def predictIris(input_data: dict, input_model_path:str):
sdk = CraftAiSdk()
f = BytesIO()
sdk.download_data_store_object(input_model_path, f)
model = joblib.load(f)
input_dataframe = pd.DataFrame.from_dict(input_data, orient="index")
predictions = model.predict(input_dataframe)
final_predictions = predictions.tolist()
return {"predictions": final_predictions}
We add the argument input_data. We choose it to be a dictionary like the one below:
{
1: {
'sepal length (cm)': 6.7,
'sepal width (cm)': 3.3,
'petal length (cm)': 5.7,
'petal width (cm)': 2.1
},
2: {
'sepal length (cm)': 4.5,
'sepal width (cm)': 2.3,
'petal length (cm)': 1.3,
'petal width (cm)': 0.3
},
}
The function returns a Python dict with one field called “predictions” that contains the predictions value. Each item of this dict will be an output of the pipeline and the key associated with each item will be the name of this output on the platform. The predictions are converted from a numpy ndarray to a list.
For that, we need to declare Input and Ouput from their SDK classes. In the terminal, please run :
from craft_ai_sdk.io import Input, Output
prediction_input = Input(
name="input_data",
data_type="json"
)
model_input = Input(
name="input_model_path",
data_type="string"
)
prediction_output = Output(
name="predictions",
data_type="json"
)
Info
Both objects have two main attributes:
-
The
nameof theInputorOutput -
For the inputs it corresponds to the names of the arguments of your pipeline’s function. In our case
name="input_data"and"input_model_path", as in the first line of function: -
For the output it must be a key in the dictionary returned by your pipeline’s function. In our case,
name="predictions"as in the last line of function: -
The
data_typedescribes the type of data it can accept. It can be one of: string, number, boolean, json, array, file. -
For the inputs we want a dictionary and a string as we specified, which corresponds to
data_type="json"anddata_type="string". - For the output, we return a dictionary which corresponds to
data_type="json".
You can then create the new pipeline by running this command in the terminal :
sdk.create_pipeline(
pipeline_name="iris-io",
function_path="iris-predict.py",
function_name="predictIris",
description="This function retrieves the trained model and classifies the input data by returning the prediction.",
inputs=[prediction_input, model_input],
outputs=[prediction_output],
container_config={
"local_folder": "src", # Enter the path to your local folder here
},
)
When the pipeline creation is finished, you obtain a return describing your pipeline (including its inputs and outputs) as below:
>> Pipeline "iris-io" created
Inputs:
- input_data (json)
- input_model_path (string)
Outputs:
- predictions (json)
>> Pipelines creation succeeded
>> {'name': 'iris-io',
'inputs': [{'name': 'input_data', 'data_type': 'json'}, {'name': 'input_model_path', 'data_type': 'string'}],
'outputs': [{'name': 'predictions', 'data_type': 'json'}]}
As our pipeline now have inputs and outputs, we can simply use it with some data. Earlier, we choose to exclude some rows of the dataset, so we can use our prediction pipeline on them. Please type in the terminal the following code :
import numpy as np
import pandas as pd
from sklearn import datasets
np.random.seed(0)
indices = np.random.permutation(150)
iris_X, iris_y = datasets.load_iris(return_X_y=True, as_frame=True)
iris_X_test = iris_X.loc[indices[90:120],:]
new_data = iris_X_test.to_dict(orient="index")
Let’s check the data we created (here is the command and the output):
print(new_data)
>> 124: {'sepal length (cm)': 6.7,
'sepal width (cm)': 3.3,
'petal length (cm)': 5.7,
'petal width (cm)': 2.1
},
41: {'sepal length (cm)': 4.5
...
We now need to encapsulate this dictionary into another one whose key is "input_data" (the name of the input of our pipeline). We also need to define the path to our trained model on the data store with the value associated to the key "input_model_path". We can do this in the terminal :
In particular, when your pipeline has several inputs, this dictionary should have as many keys as the number of inputs the pipeline have.
Execute the prediction pipeline
Finally, we can execute our pipeline with the data we’ve just prepared by calling the run_pipeline() function and passing our dictionary inputs to the inputs arguments of the function:
And getting our output like this:
This gives the output we want : with the predictions ! :
You can now check the logs on the web interface, by clicking on the Executions tracking tab of your environment, selecting your pipeline and choosing the last execution.
Success
🎉 Congratulations! You have created and ran pipeline to which we can pass new data, the path to our trained model and get predictions.
To go further, please refer to the documentation on the following subjects :