Deploy a pipeline
A deployment is a way to trigger an execution of a Machine Learning pipeline in a repeatable and automated way. Each pipeline can be associated with multiple deployments.
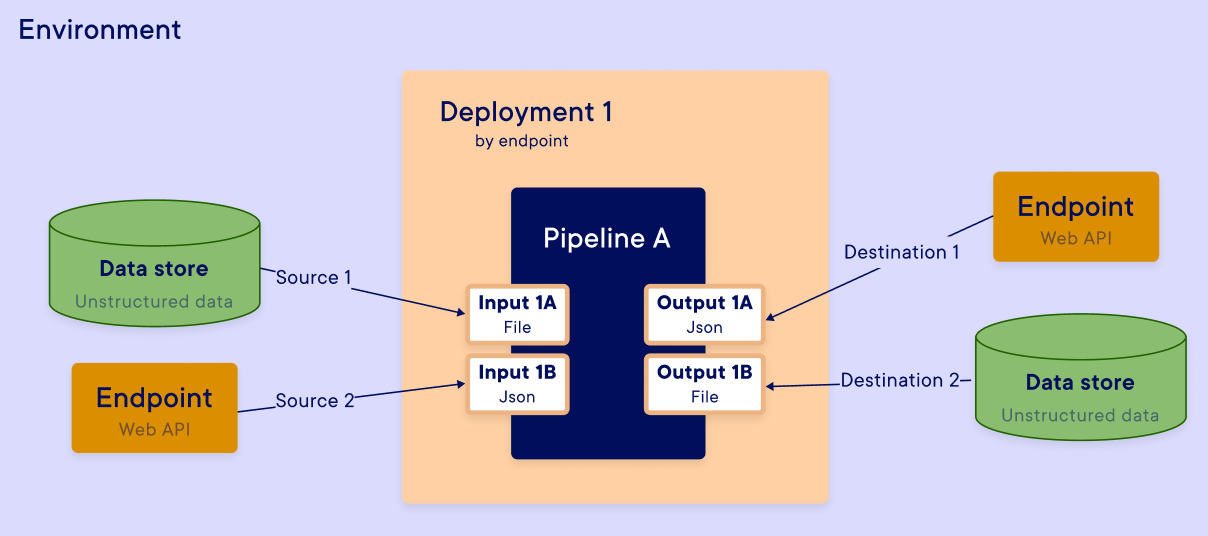
For each deployment, you can use 2 distinct execution rules :
- by endpoint (API call)
- by periodic trigger (Scheduler)
The results of the execution (predictions, metrics, data, ...) can be stored in the Data store of the environment and can be easily retrieved by the users. You can find all the information about the executions in the Execution tracking.
Create a deployment
To create an endpoint, go to the Platform, in your Project. Go to the Pipelines page and select your environment. On this page select the pipeline you cant to deploy and press the Deploy button, or click on the "..." menu on the right of the line.
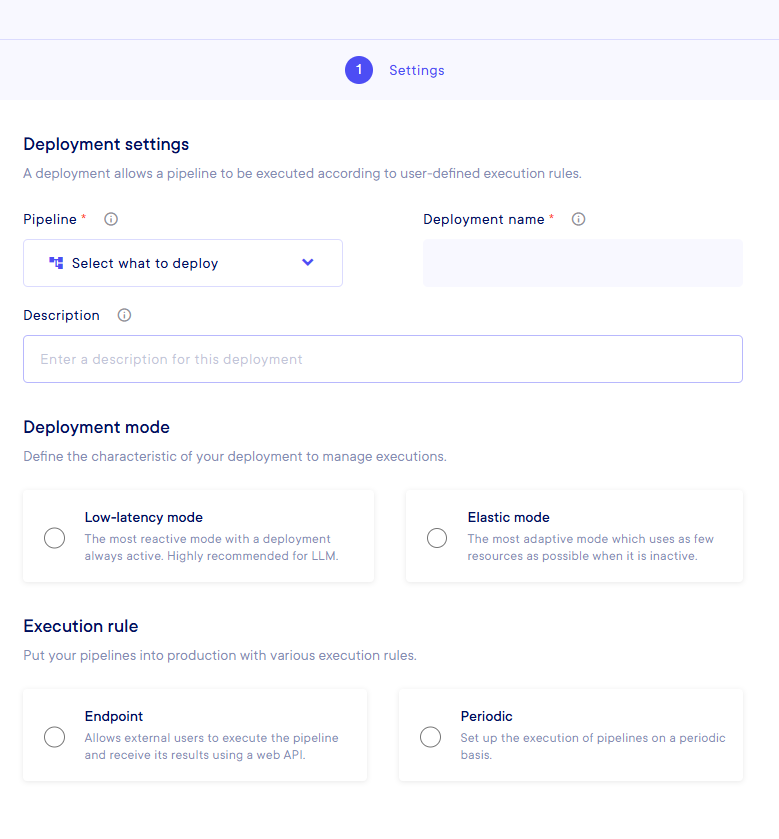
There are different Execution modes that you can use :
-
Low latency: With this option, your pipeline is always active and will be executed faster. Details are provided below -
Elastic: In the Elastic mode, the deployment enters a "stand-by" mode when it's not in use, so it preserves the environment resources
And then, different trigger conditions :
-
Endpoint: This allows automation defined by an external user call (using curl, etc.) -
Periodic: This allows automation with the use of a scheduler without any human intervention
Execution management
In Elastic mode, everything is handled by the Platform itself, so the deployments have internal information regarding their resources usage and how to manage the queue. In Low latency mode, you can specify more things such as the type of queue management you want, and the resources allocated for the current deployment.
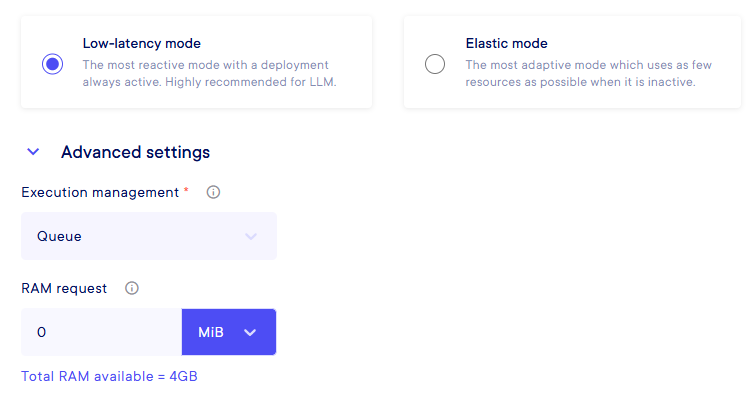
The Execution management comes with two different options :
-
Queue : A classic FIFO (First In First Out) queue management that wait for the first task to finish to start the second one. Little specificity, if a deployment fails, the next one will start and then directly after, the failed one will be retried before any other task.
-
Parallel : You need to specify the parallelism you want. It does not have an upper limit, but please, consider your total resources available an plan your parallelism accordingly.
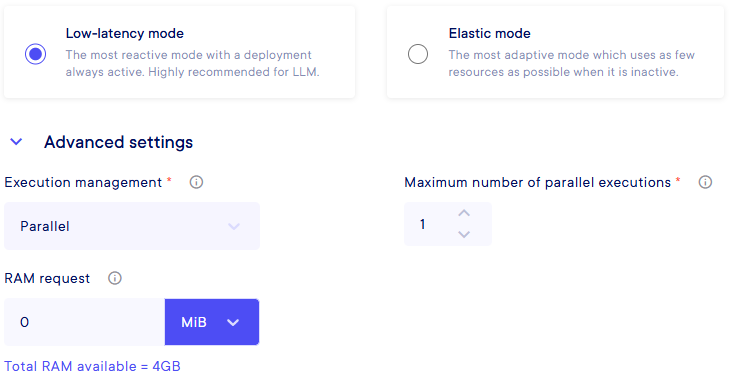
Then, you need to allow resources to your deployment to be sure that it will run when it's called (by endpoint or scheduled) in the RAM Request field. You have a reminder below of the total RAM available, keep in mind to not cross this value as the deployment may have errors. You can create a lot of deployments that in cumulative resources go over the total RAM threshold, but, if at a precise time all the current deployments cumulative RAM values are crossing over the limit, there will be issues with the Platform, like some processes stopping or being dropped totally.
You may want to think your resource planning with the following rule in mind : Keep the big processes like training in Queue mode, and the smaller ones like inference in Parallel mode. And plan this such as a Queued pipeline and several paralleled ones can run simultaneously !
Some details about Parallel Execution
When parallel executions are enabled, the pipeline's Python function is called in the pod each time a new execution starts, even if a previous execution is still ongoing, up to the number of maximum parallel executions.
Depending on how the pipeline's function was defined in the code, for each execution the function is called in a new:
- Thread if the function was defined starting with def.
- Asynchronous I/O coroutine (called with await) if the function was defined starting with async def.
We recommend that you define your pipeline's Python function with async def if you plan to use parallel executions, as this is compatible with most recent libraries. The choice mainly depends on the libraries used by your code, as some libraries may not be compatible with multiple threads, and conversely some libraries may only work with threads. If executions fail after parallel executions were enabled, try the other way to define your function.
Warnings
- Log Separation: Logs from parallel executions might be mixed up: A call to
sdk.get_pipeline_execution_logsfor one execution may return logs from another execution that was running at the same time. This should not occur with regular Python code. This can occur with logs from outside libraries that use concurrency, if logs are created (e.g. with print) without the context variables that are present when the pipeline's function is called. - Shared Memory: Executions share the same memory space, which can lead to concurrency issues and conflicts.
- Thread Safety: Ensure that the code is thread-safe to avoid race conditions and other concurrency issues.
Trigger execution
You can choose the execution trigger you want :
-
Endpoint-triggered execution : You are then presented with the URL to call this pipeline.
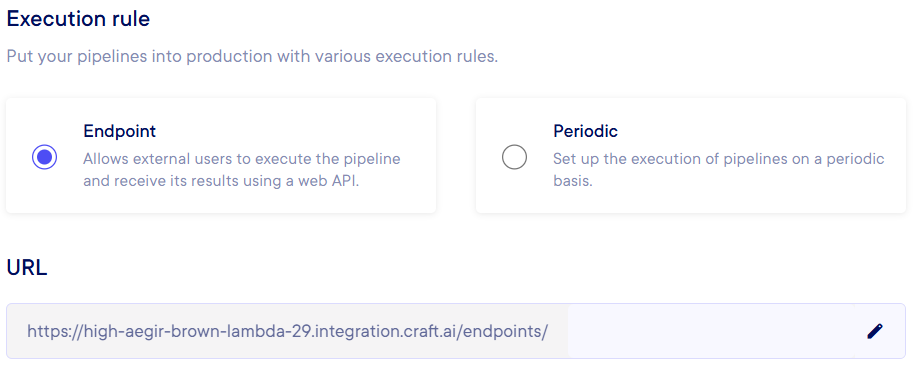
-
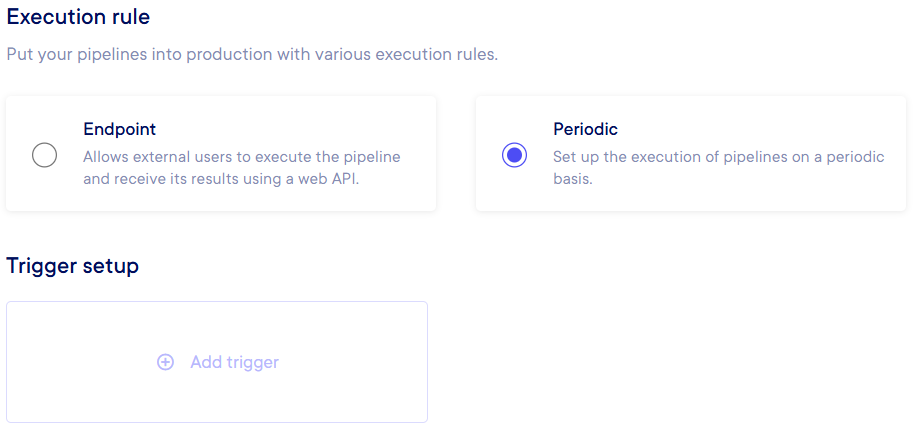
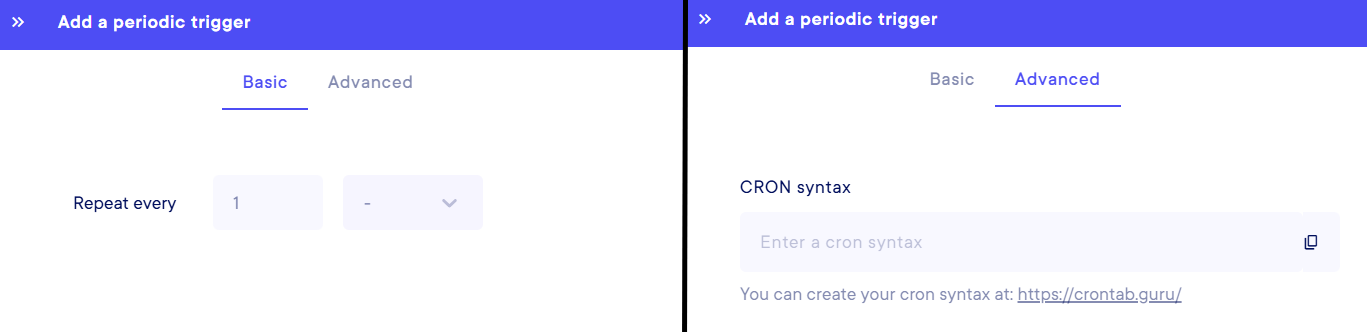
Periodic execution : You need to define a trigger that will execute your pipeline on schedule. To create a trigger, click on the "Add trigger" button, and select in the basic mode your time unit and its value, or in advanced mode the CRON configuration you want to apply (please, refer to the CRON Documentation for further details).
Input and Output mapping
If you defined Inputs and Ouput for your pipeline, you will need to do the mapping between these I/O and the places you want to access. Fill each field with your wanted parameters. It may have multiple inputs/outputs
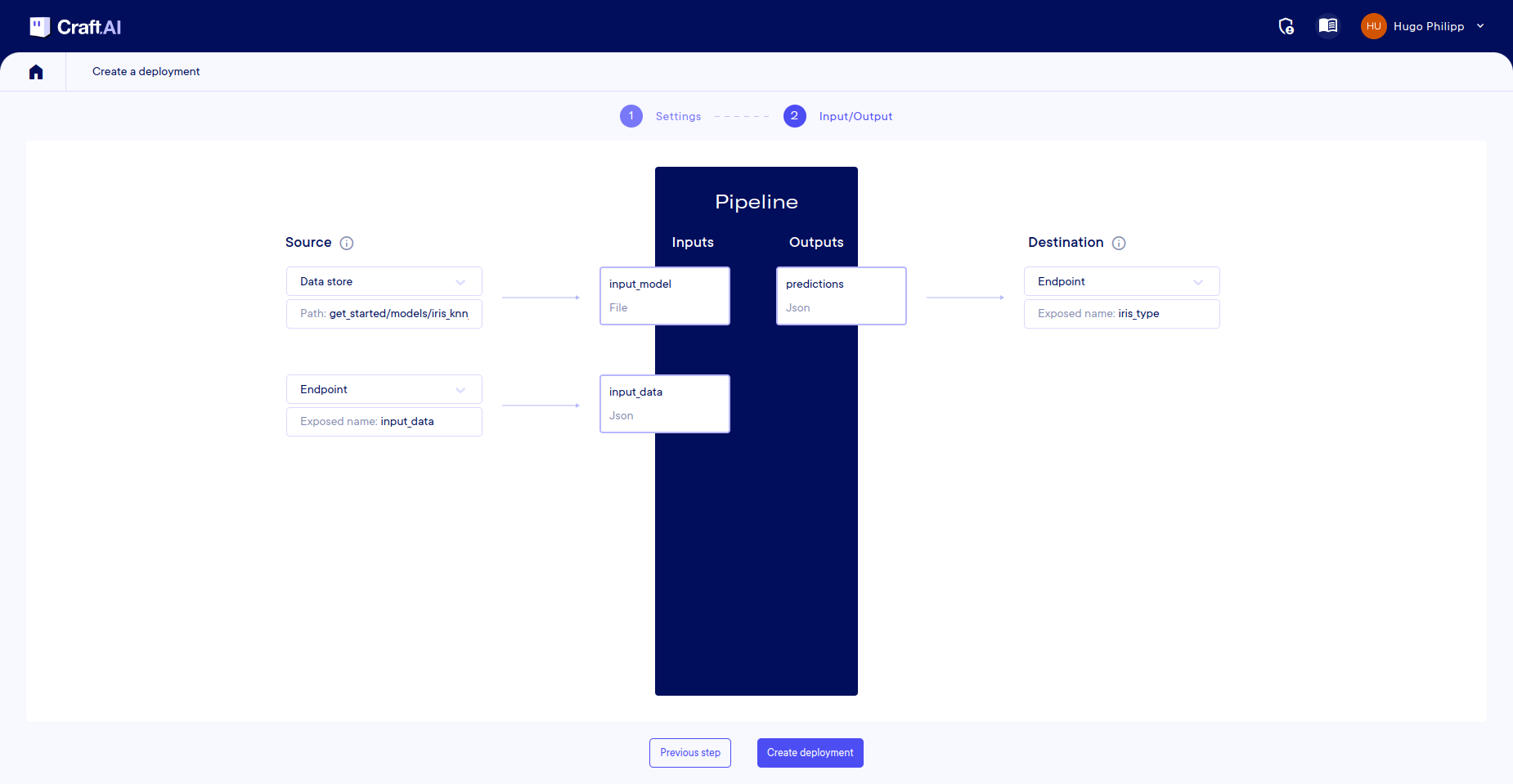 This screenshot is used for illustration purposes only, it may vary from your project depending on its own properties
This screenshot is used for illustration purposes only, it may vary from your project depending on its own properties
In the case of a sceduled deployment, you will not have the Inputs fields.
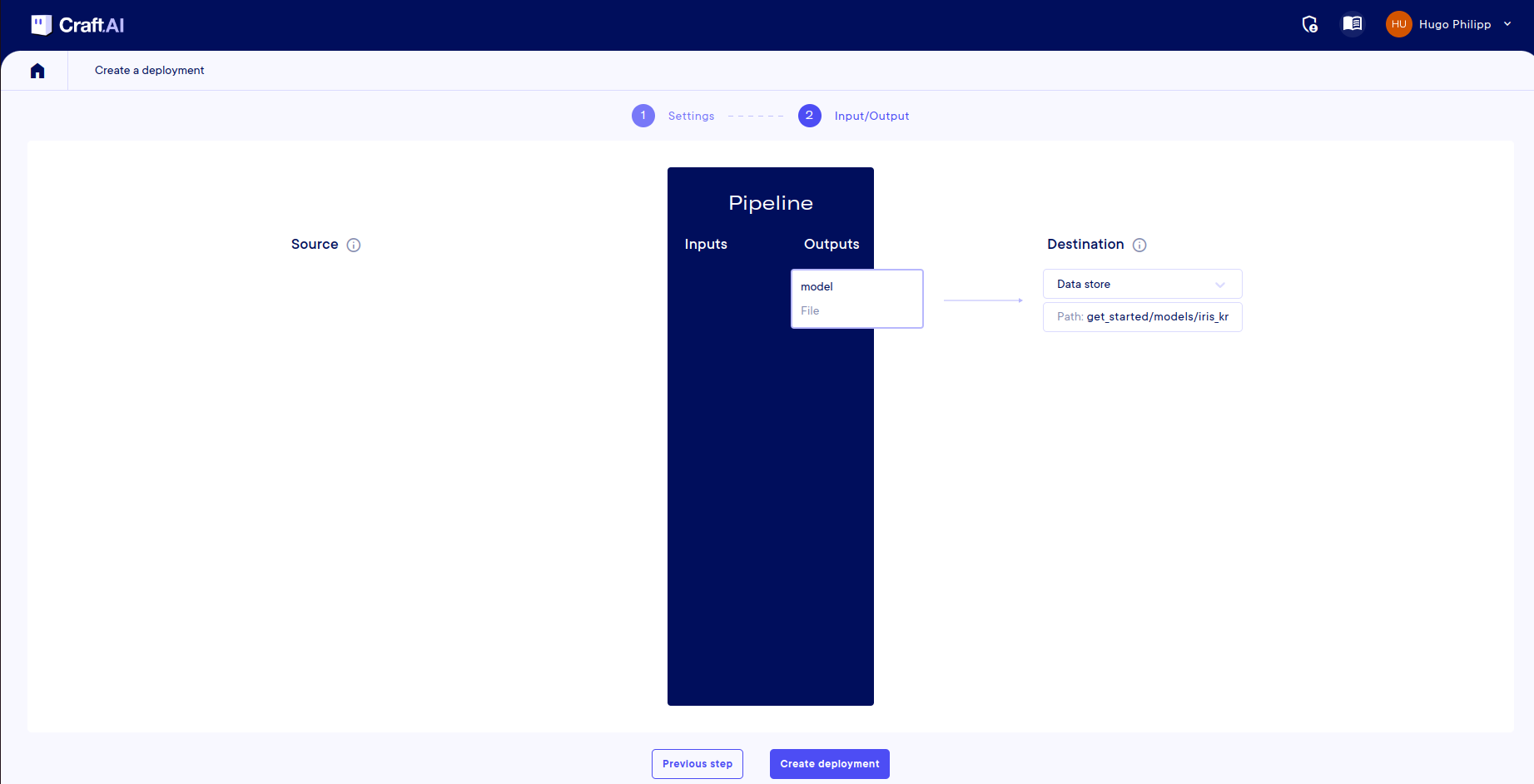 This screenshot is used for illustration purposes only, it may vary from your project depending on its own properties
This screenshot is used for illustration purposes only, it may vary from your project depending on its own properties
Get information about the Deployment
There are two ways to get information about the deployments that you created. Either with the SDK or the Platform.
Info
For the documentation about SDK functions regarding the Deployment, please refere to the SDK Documentation.