Accesssing external sources
We provide by default a Data store that allows you to store files or output results. But we know that you are using tools outside of our Platform to store other information or that you constituted datasets in a particular way. So it's possible to connect these datasources without much difference and exploit the Platform without transfering everything back and forth.
The method is rather simple, instead of just calling our Data store, you need to encapsulate this call withtin the call to your external datasource. Here is presented the setup of these environment variables, and two usages to get data from a database or to get a file from a distant bucket.
Setup
To be able to connect to an external data source, you need to specify its connection's information in the code. In our Platform, this is done with the use of environment variables. You can define them at two places, depending on the persistence you want :
- In the
Environment Settings, you can declare variables and their values. The effect will last as long as the environment exists - Directly in the code, but they will only exist during the session.
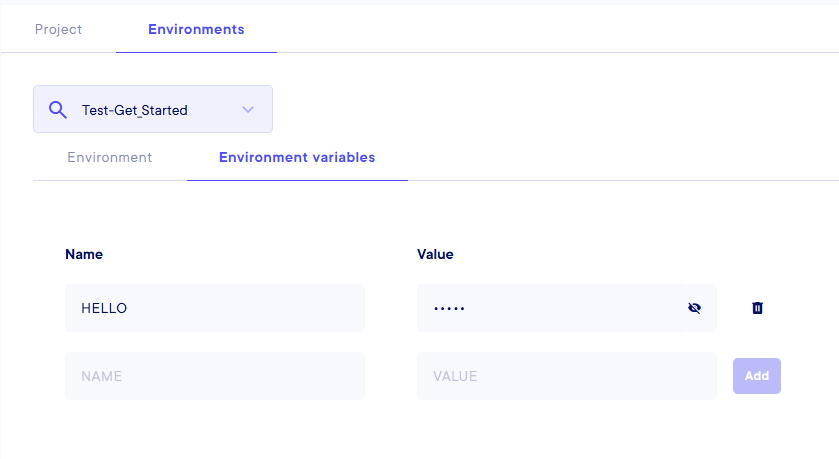
Environment Settings
You can go to the Environment settings by clicking on the ... on the environment that you want to parameter, or click on the Settings button at the top right corner (it will take you to Projects settings, and then you can select your environment in the drop-down menu in the Environment tab). Then, go to the second tab Environment variables. You can then fill every variable you need, one for each couple Name/Value.
Declare variables directly with SDK
You can declare variables with the SDK with a single command. Then, you just need to load the env so everything is accessible.
Then, in your script :
External autorisations
If the connection is not working, try to whitelist your environment URL in your data source so it accepts the connection. You can find the URL address on the environment in the Project screen.

Connect to an external Database
Now that everything has been introduce for this connection to be done, here is a concrete example of a connection to an external Database.
First, we declare all the environment variables necessary for this project.
sdk.create_or_update_environment_variable(
environment_variable_name="DB_HOST",
environment_variable_value="xxx")
sdk.create_or_update_environment_variable(
environment_variable_name="DB_ADMIN",
environment_variable_value="xxx")
sdk.create_or_update_environment_variable(
environment_variable_name="DB_PASS",
environment_variable_value="xxx")
sdk.create_or_update_environment_variable(
environment_variable_name="DB_NAME",
environment_variable_value="xxx")
sdk.create_or_update_environment_variable(
environment_variable_name="DB_PORT",
environment_variable_value="xxx")
Then we load all this variables to open a connection, and finally we fetch the data from the database.
import os
import dotenv
dotenv.load_dotenv()
DB_HOST = os.environ["DB_HOST"]
DB_ADMIN = os.environ["DB_ADMIN"]
DB_PASS = os.environ["DB_PASS"]
DB_NAME = os.environ["DB_NAME"]
DB_PORT = os.environ["DB_PORT"]
def filter_data_from_database(ids: List[int]) :
try:
# Creating a connection to the database
conn = create_db_connection(
host=DB_HOST,
user=DB_ADMIN,
password=DB_PASS,
database=DB_NAME,
port=DB_PORT
)
# Retrieving some data on the database and filtering it with the ids.
df_data_filtered = filter_data(conn, ids)
df_data_filtered_final = df_data_filtered.tolist()
finally:
conn.close()
return {"filtered_data": df_data_filtered_final}
Fetch a CSV file
With the same principles, here is an example of a connection to a CSV file. First, the variable declaration.
sdk = CraftAiSdk(
sdk_token=**our-sdk-token**,
environment_url=**our-environment-url**)
sdk.create_or_update_environment_variable(
environment_variable_name="SERVER_PUBLIC_KEY",
environment_variable_value="xxx")
sdk.create_or_update_environment_variable(
environment_variable_name="SERVER_SECRET_KEY",
environment_variable_value="xxx")
sdk.create_or_update_environment_variable(
environment_variable_name="REGION_NAME",
environment_variable_value="xxx")
And then, we get the object from the distant bucket.
import os
import dotenv
dotenv.load_dotenv()
SERVER_PUBLIC_KEY = os.environ["SERVER_PUBLIC_KEY"]
SERVER_SECRET_KEY = os.environ["SERVER_SECRET_KEY"]
REGION_NAME = os.environ["REGION_NAME"]
def filter_data_from_data_storage(bucket: str, key:str)
# Connecting to a distant storage.
client = configure_client(
public_key=SERVER_PUBLIC_KEY,
secret_key=SERVER_SECRET_KEY,
region=REGION_NAME)
# Retrieving the object in the bucket on the storage.
buffer = get_object_from_bucket(
client=client,
bucket_name=bucket,
key=key
)
dataframe = pd.read_csv(buffer)
return dataframe